关于字符编码
很早之前就碰到过”乱码”这个现象,当时非常困惑,完全不能理解发生了什么。
上大学以后,虽然开始接触计算机,不过我就没看到过具体讲解字符编码的内容。对这个领域始终是感到非常模糊。
不过,最近好像豁然开朗了一下,感觉突然就明白了这个问题。
下面我来解释一下我所理解的字符编码。
首先,所有的字符(或者说所有的信息)都是以二进制的形式存储在计算机中。所谓的编码就是 映射字符与相应的二进制之间的规则。这样的映射可以任意定义,只要大家都遵守就行了。
比如非常经典的 ASCII 码,就将英文中的字符映射为一个字节。比如,A 这个字符编码为 65,存储在计算机中为 01000001,占据一个字节。
其他的所有字符编码都是同理,比如汉字的经典编码 GBK。
以 丁 这个汉字为例,GBK 编码为 0xB6A1,存储为二进制是 10110110 10100001(直接将 B6A1 换成二进制),两个字节。
用工具查看内部字节可以看出,如图:
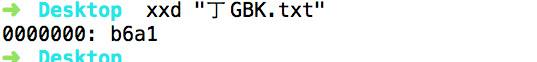
同样的道理,如果使用 utf-8 编码,丁在 Unicode 字符集中的编号为 0x4E01,但它存储在计算机中并不是简单的将 0x4E01 翻译为对应的二进制。
这里就要分清楚两个概念,字符集和字符编码。字符集是定义字符的,每一个字符在字符集中都有一个唯一的编号,Unicode 就是一个字符集,丁这个字符在 Unicode 字符集的编号是 0x4E01。
字符编码是指将字符编号变换成二进制的方法。一个字符编号,有很多种方式可以存储在计算机中。例如,我想存储编号 10,我可以存储为二进制的 20,每次在计算机中取得数字后除以二就得到了我的编号。至于为什么不直接存储编号,大多是出于兼容性和方便解码的考虑。
理解了这两个概念的不同,就能明白 utf-8,utf-16 的区别,他们都指的是 Unicode 字符集,但是代表的是不同的编码方法,同样的一个 Unicode 字符,经 utf-8 编码产生的二进制和 utf-16 编码产生的是不一样的。
utf-8 的编码机制不算很复杂,wiki 里说的很清楚,这里就不在赘述了。
现在来说说为什么要有乱码。
当计算机打开一个文本文件的时候,他必须要知道这个是什么编码的。否则无法解码,因为在计算机眼中,一切都是二进制字节(我想起了 CSAPP 中的一句话:Information Is Bits + Context)。但是不同的编码下相同的字节有不同的含义。同样是 0xABCD,在某一个编码下可能表示“丁“,在另一个编码下可能表示的就是“王”了。
打开文本文件的时候,如果不手动指定编码,大部分程序都会自动推测编码(怎么推测是另外一个话题了)。如果计算机推测的编码或者用户手动指定的编码和实际编码不符,那么自然就会出现“乱码”现象,也就是内容看上去乱七八糟,实际上在计算机看来,只是用特定的编码方式解码字符而已,只不过解码出来的字符不是你想要的。