正向代理与反向代理
代理的英文叫做 Proxy,是计算机中的常用软件。
简单来说,代理的功能犹如它的名字所示:代替某人来处理某事。
常见的代理分两种,正向代理和反向代理。不管哪种代理,它们都位于客户端和服务器之间,将我们传统的 客户端 <-> 服务器 通信变成了 客户端 <-> 代理 <-> 服务器 通信。
正向代理
正向代理用于代理客户端,此时在服务器看来,代理就是客户端,服务器不知道真正客户端的存在。
一般情况下,代理和客户端位于一个内网中,(客户端 <-> 代理) <-> 服务器。客户端不需要直接将请求发给服务器,而是发给代理,由代理代为请求服务器并返回结果。
看起来似乎是多了一道手续,没什么好处,但是实际上,正向代理有很多用处:
-
突破限制。
比如有五台服务器,位于一个内网中,但是只有一台可以访问公网。那么此时通过配置这台服务器作为正向代理,其他四台服务器便也都可以访问公网,这个场景在云服务器中很常见。
再比如我们的科学上网软件,实际上也是一个正向代理。由于我们的计算机无法直接访问敏感网站,但是代理服务器可以,而我们的计算机访问代理服务器又是没问题的。因此,通过使用代理服务器,我们便可以间接访问到我们感兴趣的网站。
-
流量控制与流量统计。
由于所有的流量都经过代理,通过配置代理,我们可以对流量进行任意控制。比如,不允许访问淘宝等,很多公司会对员工的网络访问进行限制,便是通过正向代理实现。
除了控制之外,使用正向代理也可以对流量进行统计。通过解析代理的访问日志,使用一些类似 awstats 的工具,便可以得到流量的详细统计信息。
-
提升性能。
正向代理可以缓存经常被访问的网站,从而大幅提升访问速度。
反向代理
反向代理用于代理服务器,此时在客户端看来,代理就是服务器,客户端不知道真正服务器的存在。
一般情况下,代理和服务器位于一个内网中,客户端 <-> (代理 <-> 服务器)。服务器不需要直接和客户端沟通,而是通过代理,由代理接收客户端的请求,再发送给服务器。
反向代理有如下几个用处:
-
突破限制。
比如内网中的某个服务器,如果想要在公网访问,我们可以配置内网中拥有公网IP的机器作为反向代理,从而实现对内网服务的访问。
-
负载均衡。
我们可以部署多台服务器,配置代理将请求转发给不同的服务器。这里有很多算法可以使用,比如最简单的轮流转发 (Round Robin)。这样,当负载增大的时候,客户端无需做任何修改,服务端通过简单的增加服务器便可以应对。
负载均衡的另一个好处是可以实现容灾容错。如果某台服务器宕机了,代理服务器会将请求转发到其他服务器上,客户端不会受到任何影响。
-
访问加速。
对于某些大型服务,他们的服务器遍布各地,通过使用反向代理,当请求到来时,代理可以将请求转发给最近的服务器,从而让用户在最短时间内获得响应,这一点其实和 CDN 的工作方式是一样的。
透明代理和显式代理
透明代理 这个概念只有正向代理才有,因为所有的反向代理在客户端看来都是透明的,客户端不知道请求对象是反向代理还是真正的服务器。
当使用正向代理的时候,有两种方式:
- 客户端显式配置使用代理,此时客户端知道正向代理的存在,所以是显式代理
- 客户端没有进行任何配置,但所有流量还是经过了代理,因为客户端不知道代理的存在,所以是透明代理
很多软件都提供设置代理选项,比如 Chrome,当我们在设置完代理以后,Chrome 就会使用代理进行通信,此时是显式代理。
设置代理的时候需要设置代理协议,常见的代理协议有 http,https,socks4,socks5。
HTTP CONNECT
之前我一直有个误解,认为使用 HTTP 协议是无法代理 HTTPS 流量的,其实不然。
HTTP 有一个 CONNECT 方法,可以创建一条 HTTP 隧道,用来转发任意的 TCP 流量。
通过使用 CONNECT 方法,HTTP 协议可以代理任意的基于 TCP 的协议,当然也包括 HTTPS。
假设我们配置 Chrome 使用一个 HTTP 代理,当 Chrome 遇到 HTTP 请求时,直接转发给代理,不做任何处理。
当遇到 HTTPS 请求时,Chrome 会首先使用 CONNECT 方法请求代理,请求中含有目标地址的的域名和端口,代理收到以后,会创建一条到目标地址的 TCP 链接,创建成功以后,返回 200 Connection established 给 Chrome。之后,Chrome 会将 HTTPS 数据包发给代理,而代理会原封不动的发给目标地址,代理此时就像隧道一样,沟通目标地址和客户端。
SO_ORIGINAL_DST
显式代理必须要手动配置,如果有很多客户端的话就很不方便。这个时候,我们可以使用透明代理技术。
通过在路由器层将数据包直接转发给代理软件,实现客户端无需配置,但是仍然使用代理来访问网络。
这个时候有一个问题,即代理如何知道数据包的原始目标地址?
假设我们访问百度,浏览器构建一个 HTTP 数据包,目标地址为百度 IP 和 80 端口,经过路由器的时候,路由器转发给到了代理,此时,数据包的目标地址被修改为代理 IP 和代理端口。
当代理收到数据包以后,如何知道数据包下一步该发送给谁呢?
这个问题目前我不知道确切的答案,网上有两种说法:
- 因为 HTTP/1.1 要求所有的请求必须包含
HOST头,代理可以通过解析 HOST 得到目标地址 - 通过使用
SO_ORIGINAL_DST选项获取数据包原始地址
暂时没有空去验证这个问题,这个问题的准确答案留待以后进一步明确。
一个恶作剧代理
最后,我们使用 Squid 来搭建一个恶作剧代理,这个代理会将所有的图片翻转过来。
Squid 是一个很常用的正向代理软件,可以用来做访问控制,网站缓存等等。这里我们使用 Squid 的 URL Rewrite 功能,对于所有的图片请求,将图片下载到本地,然后调用 mogrify 翻转图片,最后将翻转以后的图片返回给客户端。
这样做的效果就是,当你上网浏览时,所有的图片都是倒过来的😉,效果如下:
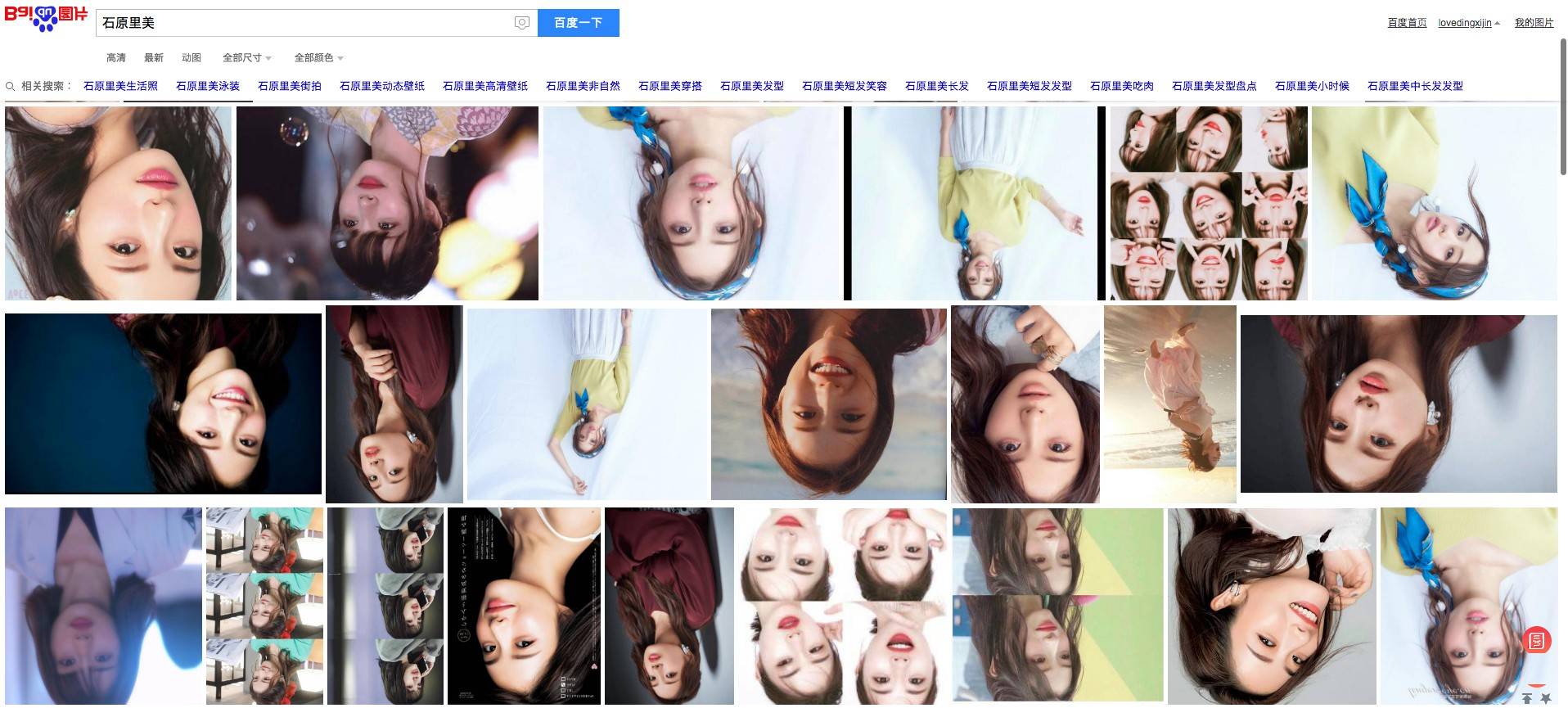
想象这样一个场景:在一个阳光明媚的午后,你发现你的邻居在蹭你的网,你并没有选择修改密码,而是默默地启动这个恶作剧代理,配置你的路由器,使用 iptables 将蹭网流量转发到这个代理。于此同时,你的邻居发现,前一刻还十分精彩的互联网世界,突然颠倒了,他苦苦思索,他不知所措,他深深地被这个世界的恶意所伤害。
关于恶作剧代理的具体代码可以去 GitHub 仓库 squid-trick-proxy-demo 上查看。