斗鱼关注人数爬取 ── 字体反爬的攻与防
之前因为业务原因需要爬取一批斗鱼主播的相关数据,在这过程中我发现斗鱼使用了一种很有意思的反爬技术,字体反爬。
打开任何一个斗鱼主播的直播间,例如 这个主播,他的关注人数数据显示在右上角:
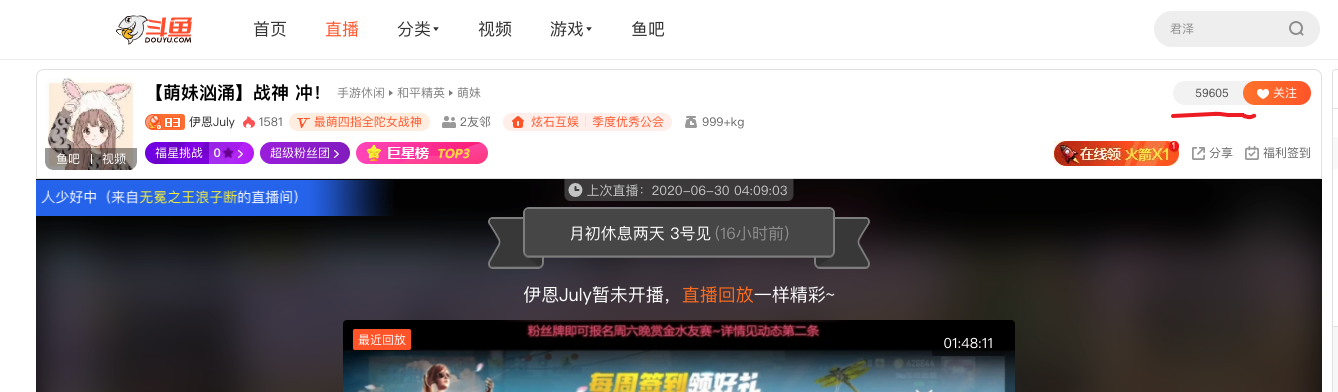
斗鱼在关注数据这里使用了字体反爬。什么是字体反爬?也就是通过自定义字体来自定义字符与渲染图形的映射。比如,字符 1 实际渲染的是 9,那么如果 HTML 中的数字是 111,实际显示就是 999。
在这种技术下,传统的通过解析 HTML 文档获取数据的方式就失效了,因为获取到的数据并不是真实数据。
下文中所谈的具体细节高度依赖斗鱼网页的实现,很有可能当你阅读这篇文章的时候已经不再是那样。虽然代码会过时地很快,但是,技巧和方法是永远不会过时的。
进攻
感兴趣的读者可以打开控制台,看看显示关注人数的那个 span 元素里面的内容,会发现根本不是显示的数字。
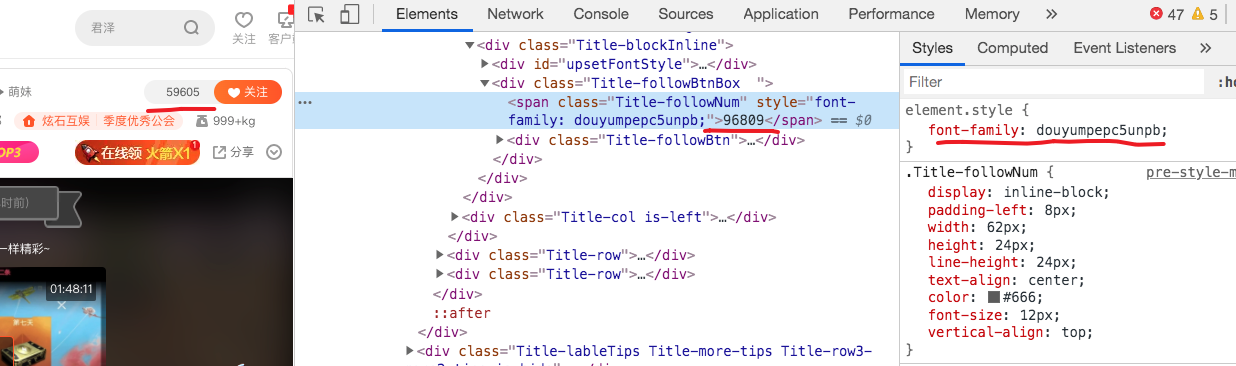
从上图可以看出,显示的是 59605,这个是真实值,但是字符却是 96809,这个是虚假值。右边的 font-family 告诉我们这个元素使用了一个自定义字体。
从 Network 面板中的我们可以找到这个字体,具体链接是 mpepc5unpb.woff。
如果大家将字体下载下来,使用如下的 HTML 代码来渲染它,我们就可以看得很清楚:
<!DOCTYPE html>
<html>
<head>
<style type="text/css">
@font-face {
font-family: test;
src: url(mpepc5unpb.woff);
}
div {
font-family: test;
font-size: 80px;
text-align: center;
margin: 200px 0;
}
</style>
</head>
<body>
<div>
0123456789
</div>
</body>
</html>
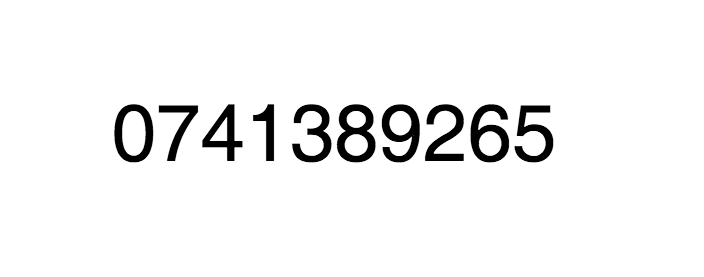
在这个字体中,字符 0 会渲染图形 0,字符 1 会渲染图形 7,以此类推,因此,HTML 中的字符 96809 渲染的图形就是 59605。
这个原理不难理解,我们甚至不需要知道字体文件内部的具体格式。因为不管怎样,字体内部一定有一个映射关系。这个关系规定了什么样的字符渲染什么样的图形。
正常情况下,字符 1 对应的图形是 1 的形状,但是通过修改字体,我们就可以让字符 1 对应的图形是 9 的形状,或者说,其他任意形状。
这样以来,HTML 中的字符就完全失去了意义,这个字符所代表的的含义要依据字体来定。
上面这个字体实际上定义了一个 0123456789 到 0741389265 的映射,拿到 HTML 中的字符我们需要根据这个映射才能得到真正的值。
刷新斗鱼你会发现,字体又变了,所以它那边肯定是有一个字体库的,但是这个不关键,解决一个就解决了所有。
那么,如何解决字体反爬从而得到真实关注人数?
分析
现在我们知道,如果要获取关注人数,我们必须要获取
- HTML 中的原始值,也就是假值
- 字符与真正数字之间的映射关系
这两个问题都不太好解决,我们先谈第一个。
斗鱼的这个关注人数很明显是 JS 渲染的,我们有两条路可以走:
- 使用 Headless Browser。也就是使用一个完整的浏览器来渲染整个页面,然后获取 DOM 中的值。这个是兜底办法,永远可行,但是缺点是效率太差。大家可以看一下打开斗鱼直播间页面的速度,正常情况下等到关注人数显示的时候至少需要 5 秒钟。
- 我们找到数据源。找到斗鱼的 JS 是请求了哪个接口获取到了数据,然后直接请求该接口。
第二个办法的效率会高很多,但是同时也困难很多。因为 JS 通过什么手段获取了数据实在是灵活性太高了,有太多的办法:
- 可以请求多个接口,然后拼接得到数据
- 可以请求某个接口,返回变形后的数据,然后 JS 再反向处理
- 组合上面两种方式
- …
面对一堆压缩后的 JS 代码,我们想通过分析代码的方式来找到数据源是不可行的。不过我们还是有别的手段,这个后面再说。
考虑到性能以及让生活变的更有乐趣,这里我们选择第二种办法。
现在我们来看第二个问题,也就是如何通过字体来获取映射关系。
通过解析字体文件可以办到吗?不可以,字体文件中存储的是字符和图形的映射,那么对于一个图形,它是我们眼中的 “0” 还是我们眼中的 “1” 字体文件也没法知道,在字体文件眼中就是一堆坐标。
那还能怎么办呢?只能渲染好以后找个人来看吗?
如果时光倒退 20 年回到 2000 年,恐怕只能这样做了。虽然那个时候也有图形识别技术,但是不像现在这样成熟也不像现在这样随手可得。
但是现在是 2020 年,OCR 图形识别技术已经非常成熟了,我们随便找个 OCR 库应该就够用了。
所以这个问题的解决方案也有了,我们使用字体渲染好图形,然后调用 OCR 识别图形对应的数字便可以获取到映射关系。
按照这个思路,我们整个流程便是
- 寻找数据源
- 根据数据源获取字体文件和假数据
- 根据字体文件渲染图形
- 使用 OCR 识别图形得到映射关系
- 根据映射关系和假数据得到真数据
数据源
现在我们来找数据源,看看斗鱼的 JS 到底是从哪里获取的字体信息和假数据。
这其实是一个很有意思的过程,我建议有兴趣的同学先暂停下来,花点时间自己试着找找,看能不能找到。
我的第一个想法很简单,JS 一定是通过某个接口得到了这些数据,那么,我们把所有网络请求导出为 HAR 格式,然后在里面搜索试试。
点击上图中标记为红色的按钮就可以导出请求为 HAR 格式,HAR 是一个文本格式,非常有利于搜索。
我试了用假数据也就是 96809 和字体 ID mpepc5unpb 来搜索,都没有任何结果。
只能说我们的运气不太好,这里情况实在太多了,有可能返回的值经过了一定的处理比如 base64 或者 rot13,也有可能是多接口返回然后再拼接组装。我们没办法进一步验证,只能放弃这条路。
其实在大部分情况下,使用关键词搜索一下 HAR 是很有效的手段,很容易找到对应的接口。
既然此路不通,我们换个思路,请求到了数据以后,JS 代码一定会调用相关 API 去修改 DOM,能不能监听到这个动作?在它修改 DOM 的时候打上断点,这样就可以通过调用栈知道是哪段 JS 在做此操作,然后顺腾摸瓜找到对应的接口。
答案是是可以的,通过使用 MutationObserver 我们可以监听任意 DOM 的修改事件。
new MutationObserver((mutations, observer) => {
const el = document.querySelector("span.Title-followNum")
if (el != null) {
observer.disconnect()
new MutationObserver((mutations, observer) => {
debugger
}).observe(el, {childList: true, subtree: true})
}
}).observe(document, {childList: true, subtree: true})
通过 Tampermonkey 加载上面的代码,刷新,等待断点触发。
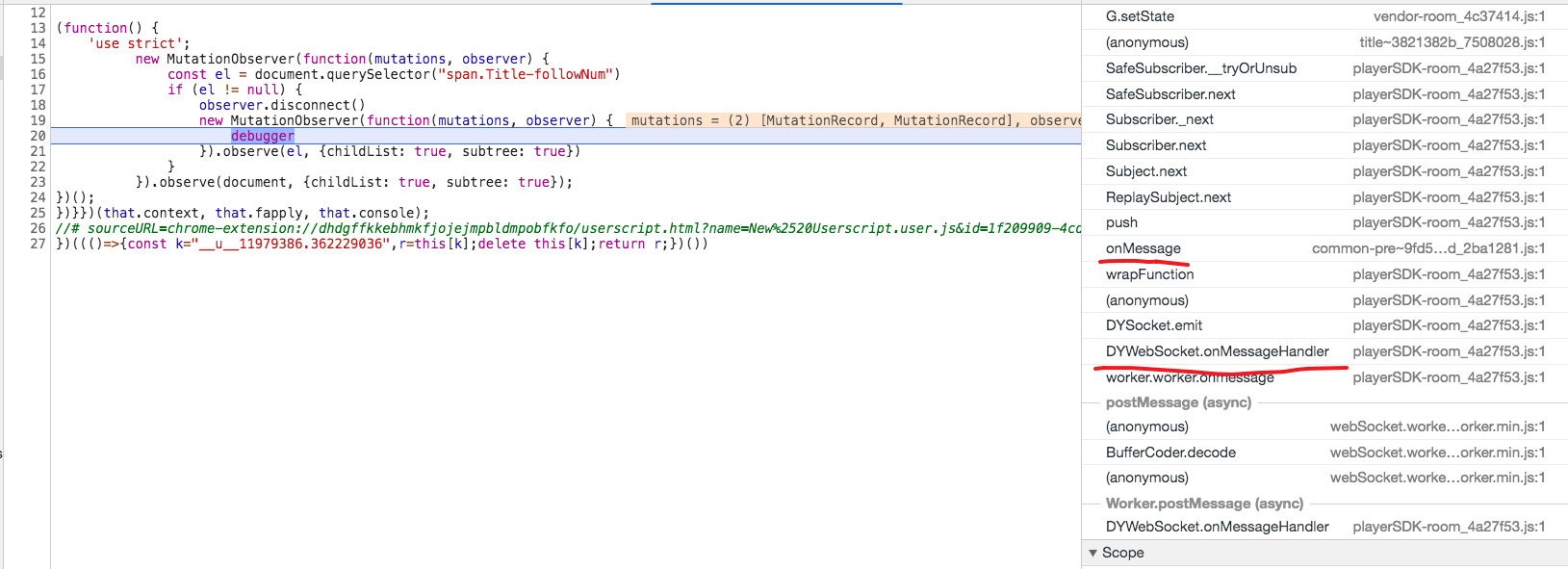
从上面的调用栈可以看出,数据来源自 WebSocket。
去 Network 面板中看一下,果然是这样。
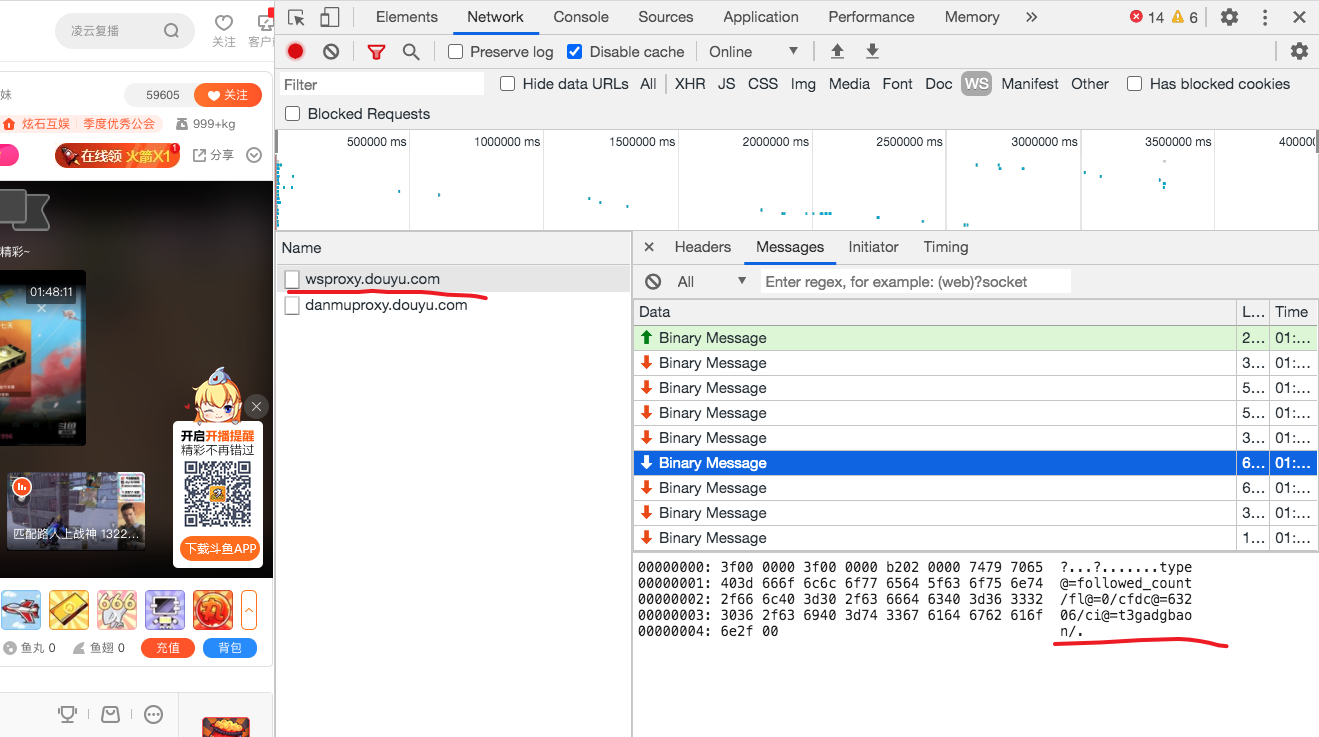
之后爬取像斗鱼这样的复杂网站,应该先检查一下 WebSocket 中的消息。
这个消息格式很好理解,我们可以猜到 cfdc@=63206 表示字符为 63206,ci@=t3gadgbaon 表示字体 ID 是 t3gadgbaon,和 DOM 对照一下,确实如此。
至此我们的数据源问题解决了一半,我们知道了数据是来自 WebSocket 发送的响应。但是,如何程序化去获取这个响应?
协议
分析 WebSocket 消息会发现,客户端连接以后会发送一条登录消息,然后服务端会回复多个消息,其中,就有我们感兴趣的 followed_count。
客户端发送的消息如下:
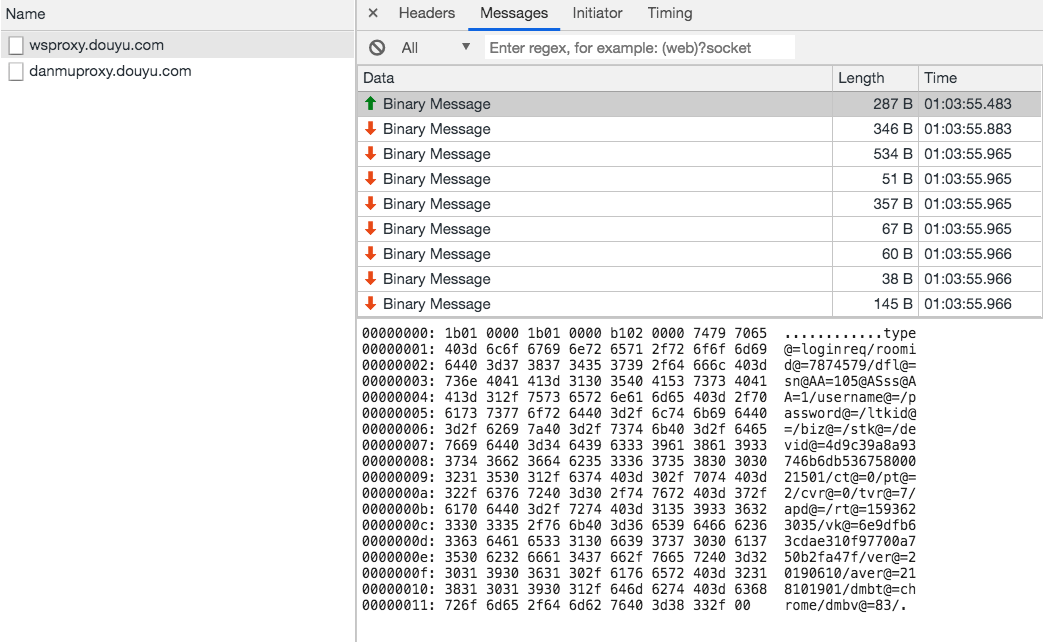
虽然是二进制消息,但是可以看到消息主体都是可读的文本,很明显,斗鱼这里是自己实现了一个内部协议格式。
开头 12 个字节暂时不清楚什么含义,然后紧跟着一段键值对数据,使用 @= 连接键和值,使用 / 分割,最后跟上 /\x00。
多查看几个直播间以后,对于开头的 12 个字节,我们不难分析出前四个字节和消息长度有关,使用 Little Endian,中间四个字节和前四个字节相同,而最后四个字节是固定值 0xb1 0x02 0x00 0x00。
上面的消息长度是 287 个字节,而 0x0000011b = 283,所以,长度编码的值实际上是整个消息的长度减去 4。
这里设计其实挺奇怪的,长度信息比实际长度少了四个字节,同时开头又多了四个字节的冗余数据,怎么看怎么都像是设计失误,第二个四字节是多余的。
对于一个协议来说,作为外部人员,我们是永远无法弄清楚有些问题的成因的。可能这四个字节有其他用处,可能就是设计失误,也有可能一开始没有这四个字节,后来因为 bug 不小心加上了,然后为了后向兼容,就一直带上了。
现在我们来看具体的键值对:
type@=loginreq
roomid@=7874579
dfl@=sn@AA=105@ASss@AA=1
username@=
password@=
ltkid@=
biz@=
stk@=
devid@=4d9c39a8a93746b6db53675800021501
ct@=0
pt@=2
cvr@=0
tvr@=7
apd@=
rt@=1593623035
vk@=6e9dfb63cdae310f97700a750b2fa47f
ver@=20190610
aver@=218101901
dmbt@=chrome
dmbv@=83
这些参数中,type, roomid, devid 都很好理解,dfl, ver, aver, dmbt, dmbv 这些看起来像是不重要的信息携带字段。
rt 很容易发现是一个秒级时间戳,现在唯一剩下的就是 vk 这个字段。我们可以通过修改字段值的方式来大致判断字段的作用和重要性。
如果我们原封不动的使用这个请求体(在检查器中右键选择 Copy message... -> Copy as hex)请求斗鱼的 WebSocket 服务,会发现一开始是有正常响应的,但是过几分钟后就报错了。
const WebSocket = require("ws")
const ws = new WebSocket("wss://wsproxy.douyu.com:6672/")
ws.on("open", () => {
ws.send(Buffer.from("1b0100001b010000b102000074797065403d6c6f67696e7265712f726f6f6d6964403d373837343537392f64666c403d736e4041413d31303540415373734041413d312f757365726e616d65403d2f70617373776f7264403d2f6c746b6964403d2f62697a403d2f73746b403d2f6465766964403d34643963333961386139333734366236646235333637353830303032313530312f6374403d302f7074403d322f637672403d302f747672403d372f617064403d2f7274403d313539333632333033352f766b403d36653964666236336364616533313066393737303061373530623266613437662f766572403d32303139303631302f61766572403d3231383130313930312f646d6274403d6368726f6d652f646d6276403d38332f00", "hex"))
})
ws.on("message", payload => {
console.log(payload.toString())
})
很明显,斗鱼会校验 rt 的值,如果服务器时间和 rt 时间超过一定间隔,那么会返回错误,这是一个很常见的设计。
如果我们修改了一下 vk,也会得到一个错误,这说明 vk 是类似签名的东西,而不是什么信息携带字段,服务端会校验它的有效性。
对于 dfl, ver, aver, dmbt, dmbv 这些字段,我们会发现随便修改都不会影响结果,说明我们的之前的猜测是正确的。
所以,现在剩下的问题就是要搞清楚 vk 的签名规则,这个只能从源码入手。
Chrome 检查器中对于每个网络请求都会显示它的 Initiator,也就是这个请求是什么代码发起的。
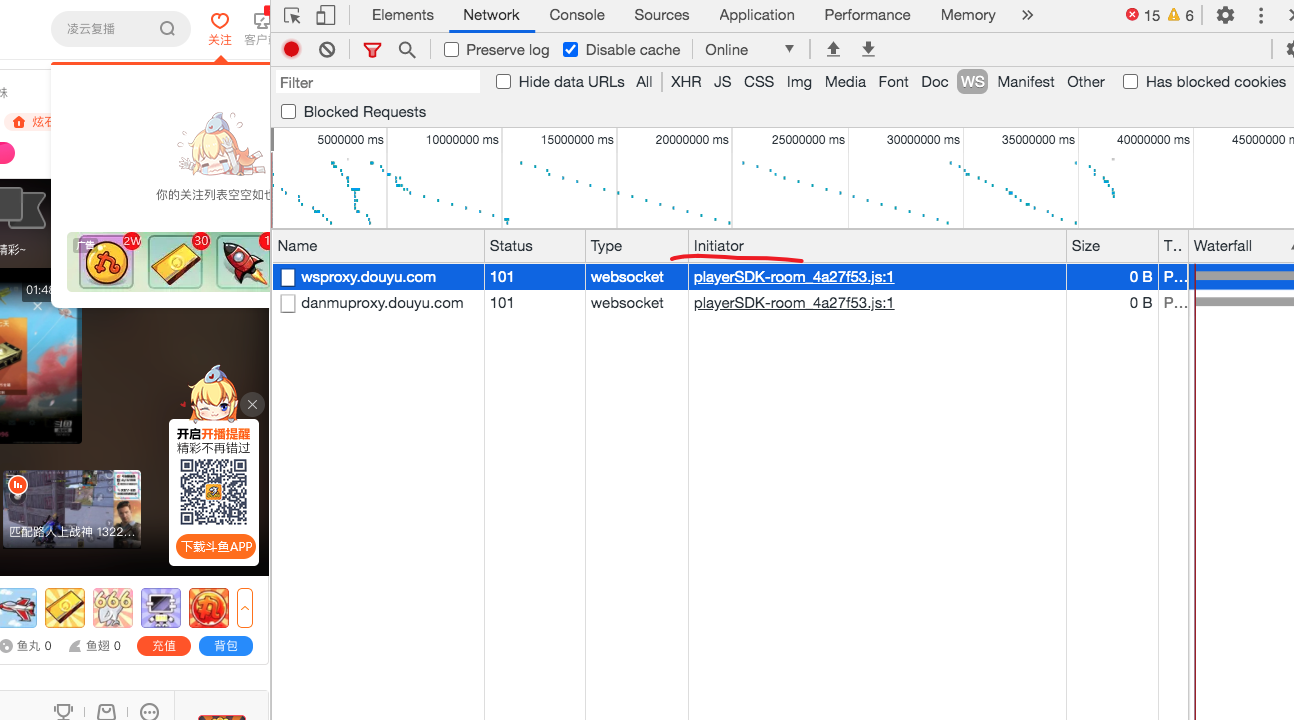
鼠标放上去可以看到完整的调用栈。
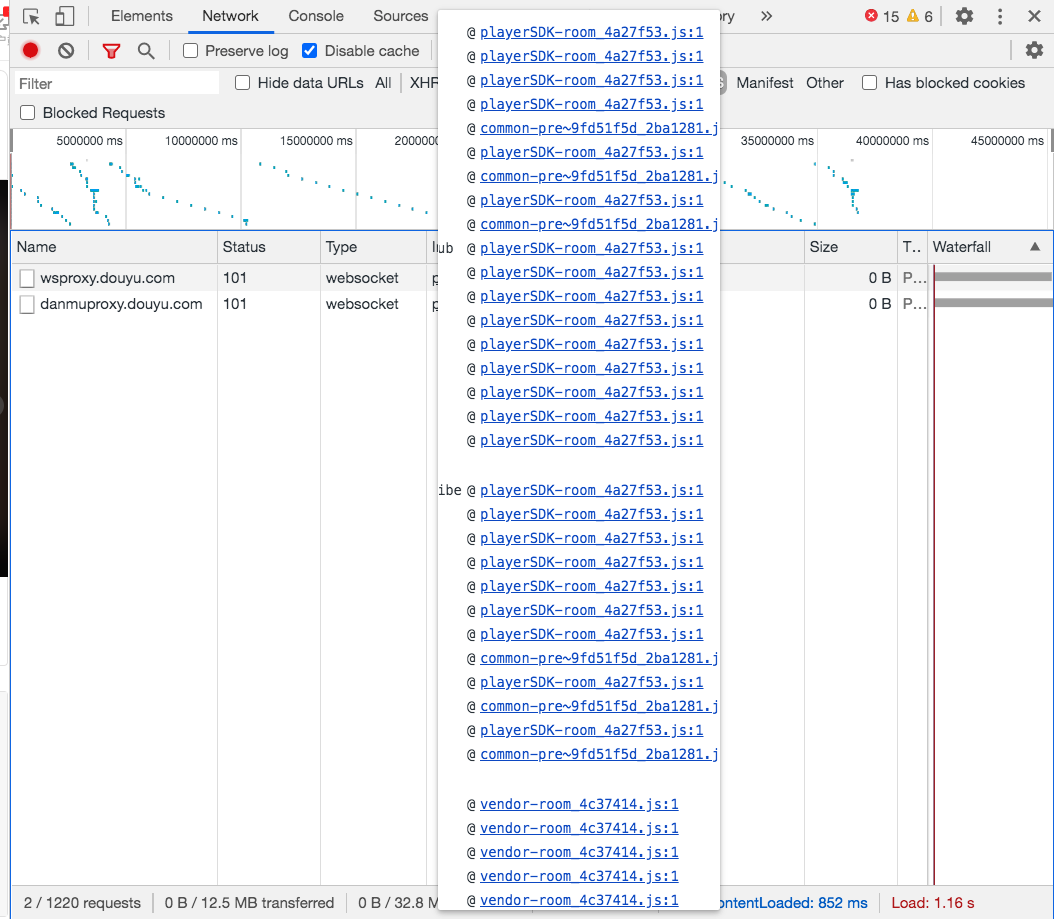
我们的思路是找到发送消息的地方,打上断点,通过调用栈往上找。
所以打开最上面的 playerSDK-room_4a27f53.js 文件,搜索关键字 send,很容易找到下面这段代码。
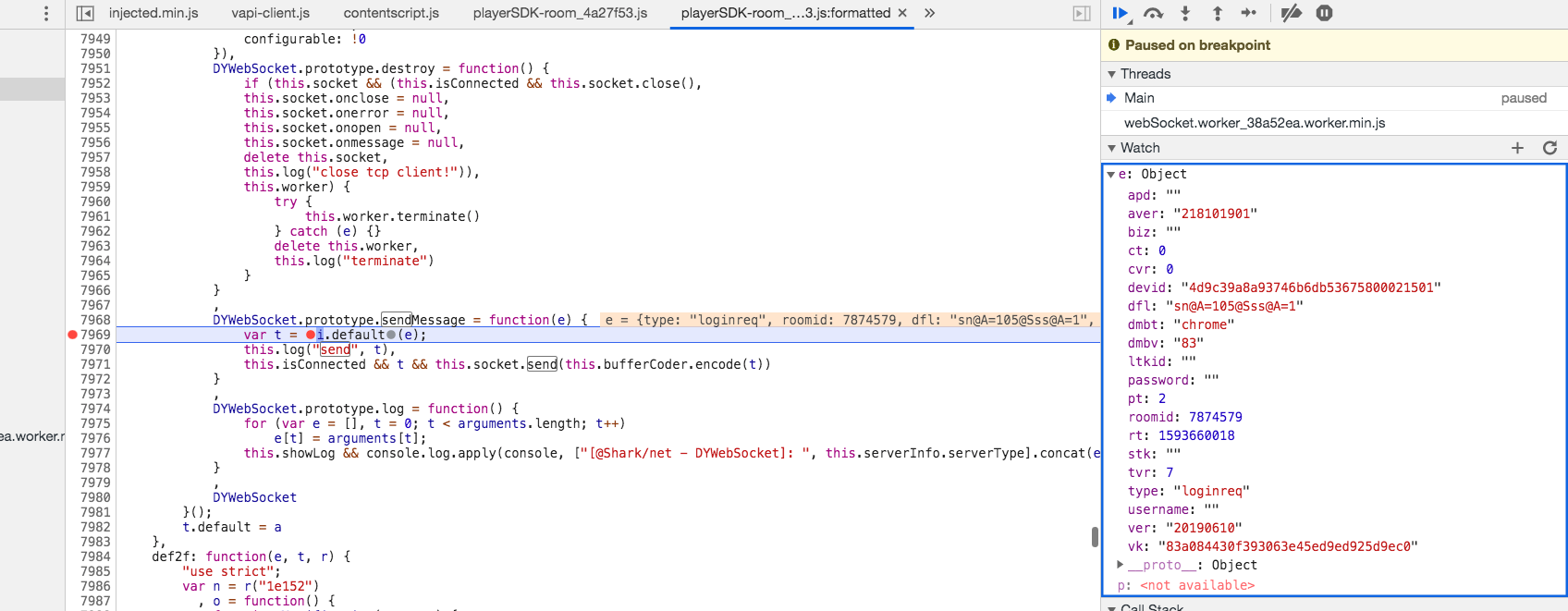
通过断点我们可以看出,登录消息就是通过这里发送的,因为 e 是登录的消息体。
展开调用栈,会发现有一个函数叫做 userLogin,点进去。
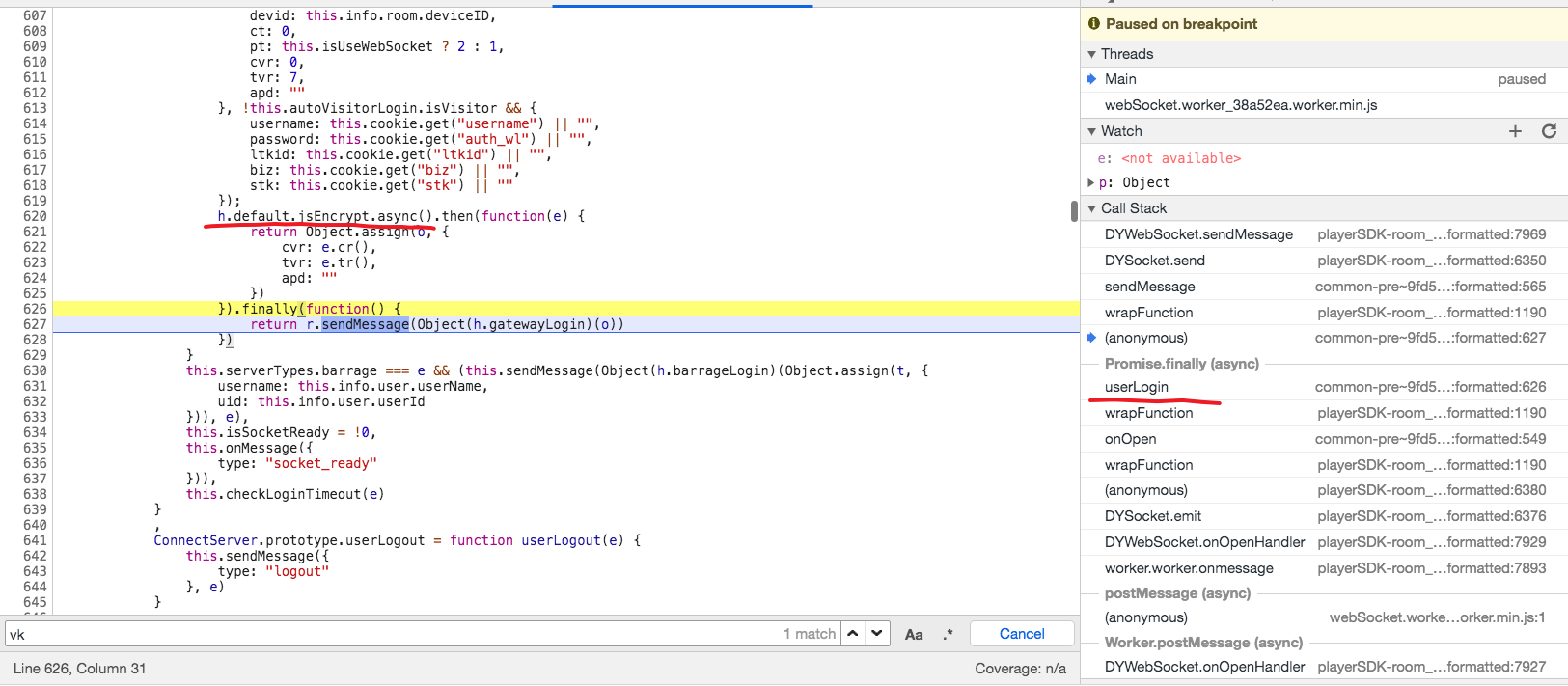
可以发现我们来到了 common-pre~9fd51f5d.js 文件,可以猜到 h.default.jsEncrypt.async() 这段代码应该就是签名相关的代码。
我们可以断点进这个函数,然后继续找。或者,我们直接搜索 vk。
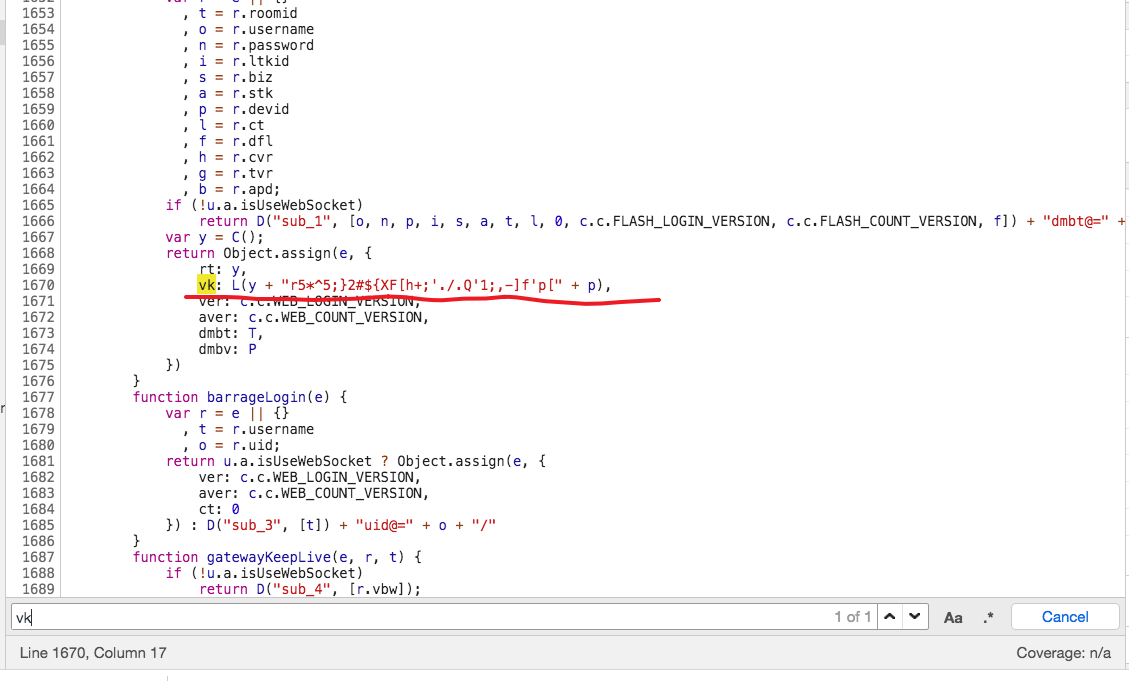
然后我们就发现 vk 的值等于 L(y + "r5*^5;}2#${XF[h+;'./.Q'1;,-]f'p[" + p)。到这里就简单了,通过断点可以发现 y 就是 rt,p 是 devid,而 L 是一个求 md5 值的函数。
所以 vk 的签名算法是 vk = md5(rt + "r5*^5;}2#${XF[h+;'./.Q'1;,-]f'p[" + devid)
现在整个消息体的结构我们都清楚了,我们试着构造消息体请求斗鱼服务器看看能不能得到响应。
const encode = obj => Object.keys(obj).map(k => `${ k }@=${ obj[k] }`).join("/")
const decode = str => {
return str.split("/").reduce((acc, pair) => {
const [key, value] = pair.split("@=")
acc[key] = value
return acc
}, {})
}
const crypto = require("crypto")
const md5Hash = crypto.createHash("md5")
const md5 = payload => {
return md5Hash.update(payload).digest("hex")
}
// 4-byte length, 4-byte length, 0xb1, 0x02, 0x00, 0x00
const getPayload = obj => {
const arr = [0, 0, 0, 0, 0, 0, 0, 0, 0xb1, 0x02, 0x00, 0x00]
const objEncoded = encode(obj) + "/\x00"
arr.push(...objEncoded.split("").map(c => c.charCodeAt(0)))
const payload = Buffer.from(arr)
const dv = new DataView(payload.buffer, payload.byteOffset)
const length = payload.length - 4
dv.setUint32(0, length, true)
dv.setUint32(4, length, true)
return payload
}
ws.on("open", () => {
// 这个随便填写一个
const devID = "4d9c39a8a93746b6db53675800021501"
const rt = (new Date().getTime() / 1000) >> 0
const obj = {
type: "loginreq",
roomid: roomID,
devid: devID,
rt: rt,
vk: md5(rt + "r5*^5;}2#${XF[h+;'./.Q'1;,-]f'p[" + devID),
}
const payload = getPayload(obj)
ws.send(payload)
})
ws.on("message", payload => {
const data = decode(payload.slice(12).toString())
if(data.type === "followed_count") {
console.log(data)
} else {
console.log(data.type)
}
})
成功了!
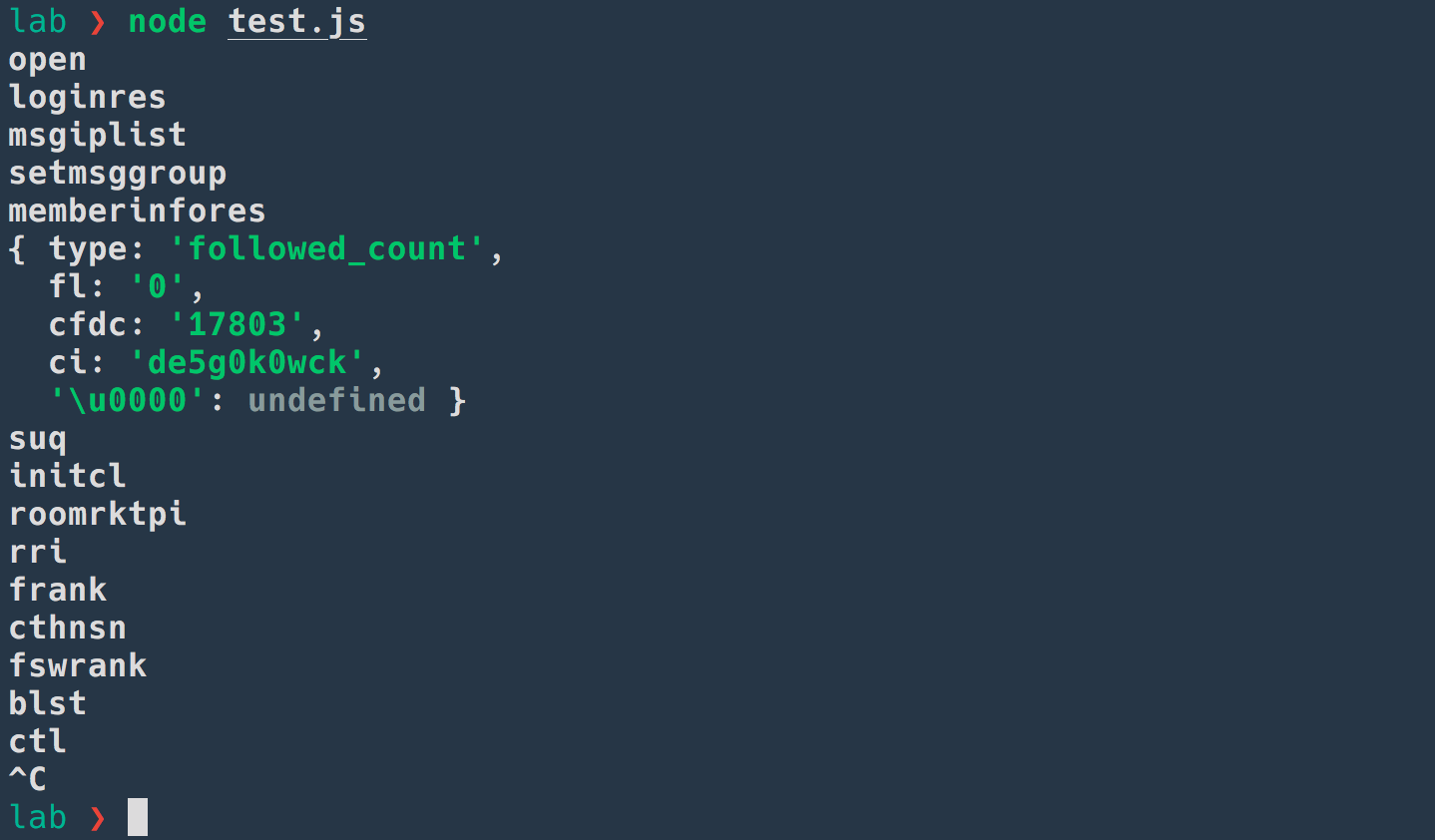
OCR
获取到字体 ID 和假数据以后,接下来我们要做的就是使用字体渲染一张图片,然后调用 OCR 工具识别图片。
我们先使用字体 ID 将字体下载下来,字体的下载 URL 是固定的 https://shark.douyucdn.cn/app/douyu/res/font/FONT_ID.woff。
怎样渲染字体到图片呢?这个问题方案有很多,上文中我们利用了浏览器,这里我选择使用 SDL。
#include <stdio.h>
#include <SDL2/SDL.h>
#include <SDL2/SDL_ttf.h>
#include <SDL2/SDL_image.h>
int
main(void)
{
if(TTF_Init() == -1) {
printf("error: %s\n", TTF_GetError());
return 1;
}
TTF_Font *font = TTF_OpenFont("test.woff", 50);
if(font == NULL) {
printf("error: %s\n", TTF_GetError());
return 1;
}
SDL_Color black = { 0x00, 0x00, 0x00 };
SDL_Surface *surface = TTF_RenderText_Solid(font, "0123456789", black);
if(surface == NULL) {
printf("error: %s\n", TTF_GetError());
return 1;
}
IMG_SavePNG(surface, "test.png");
return 0;
}
SDL 渲染速度非常快,结果也很清楚,用来 OCR 应该足够了。
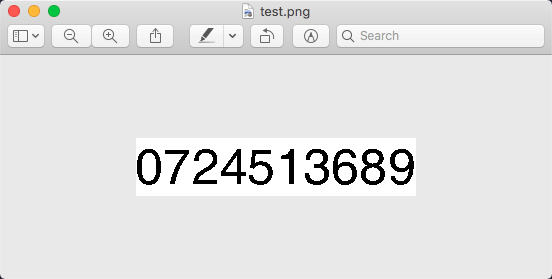
图形识别这一块我并没有什么太多经验,但是没关系,感谢开源世界。我们 Google OCR,很容易就会找到一个看起来很厉害的库 tesseract。
先安装它 brew install tesseract。
项目本身是 C++ 的,我们可以直接用 C++ 调用。但是因为后面我打算使用 Go 写一个完整的关注人数爬虫,所以这里我们使用 Go 来调用。
安装 Go 的绑定 gosseract,然后使用如下代码来试试:
package main
import (
"fmt"
"github.com/otiai10/gosseract/v2"
)
func main() {
client := gosseract.NewClient()
defer client.Close()
client.SetImage("test.png")
client.SetWhitelist("0123456789")
text, _ := client.Text()
fmt.Println(text)
}
然后我们很顺利地就得到了结果,开源万岁!🎉

最终实现
最后,我们把上面的各个步骤整合一下,使用 Go 来实现一个完整的斗鱼关注人数爬虫,最终的代码在这里 douyu-crawler-demo。
代码的大致流程如下:
- 启动一定数量的 worker
- 通过 channel 发送 roomID 给到 worker
- worker 爬取关注人数
- 首先通过 WebSocket 获取字体信息和假数据
- 下载字体到缓存目录中
- 调用 SDL 渲染字体为图片到缓存目录中
- 使用 OCR 识别图片得到映射关系
- 存储映射关系(生产肯定是写入数据库,这里是 demo,我们使用文件)
- 输出结果(同样,生产是写入数据库,这里我们写入到结果文件)
当然,如果要做一个生产级别的爬虫,还有很多问题要处理:
- 日志:详细的日志可以帮助分析问题,改进不足以及恢复数据等。
- 错误处理:爬虫的天然属性就是随时可能无法工作,完善的错误处理和报警机制是必须的。
- 重试机制:很多接口会报错,需要有一定的重试机制。
- 数据校验:每一步获取到的数据都需要校验有效性,否则很容易在数据库中写入无效数据。
- 人工干预:有些环节比如 OCR 的准确率是无法做到 100% 的,要考虑到失败的情况,一旦 OCR 识别失败,需要引入人工干预流程。
- IP 池:很多接口会限制 IP 的访问频率,这个时候要挂 IP 池。
最后,我们来测试一下我们的程序效果。roomids.txt 中含有 120 个斗鱼主播的 roomID,我们使用爬虫来爬取这 120 个主播的关注人数。
$ douyu-crawler-demo -f roomids.txt
....
2020/07/02 13:28:41 all done in 36.313598957s
2020/07/02 13:28:41 total: 120
2020/07/02 13:28:41 success: 86
2020/07/02 13:28:41 error: 34
2020/07/02 13:28:41 ocr failed: 0
120 个主播,一共花费了 36s,这个速度还是非常理想的,使用 Headless Browser 是不可能有这个速度的。
但是我们会发现,其中有一些失败了,看日志主要是 WebSocket 没有返回值或者超时了,这在爬虫中很正常,直接重试一下就行了。
$ douyu-crawler-demo -f roomids.txt
...
2020/07/02 13:29:42 all done in 23.660793712s
2020/07/02 13:29:42 total: 120
2020/07/02 13:29:42 success: 120
2020/07/02 13:29:42 error: 0
2020/07/02 13:29:42 ocr failed: 0
这次全部成功了,结果文件在 result/result.txt 中。
可以发现 OCR 没有一次失败,tesseract 太赞了👍
$ head result/result.txt
5324388,b72iyfidmi,5538567,1169154
582074,yzs37nb5ik,447330,116880
6937618,21lwetbnlg,579241,128374
5632185,flecd9ycbg,495291,327621
6794440,21lwetbnlg,80850,90910
52319,tcmpj93mbl,452436,576593
820795,n1kril0e2r,80063,40025
5168755,5n5pkb33y,861526,689528
8546776,84c209m14f,9869,3783
5747228,svk3del36j,319692,127978
每个字段分别是房间号、字体 ID、假数据以及真数据。
防守
讲完了进攻,现在我们来看看如果我们站在防守方,需要使用这种技巧来反爬,该怎么做?
字体反爬的核心是随机生成一个映射,根据映射生成字体,然后返回字体和假数据给到前端。
这个时候我们就需要了解一下字体的文件格式了。常见的字体格式有 ttf, otf, woff。其中 woff 是一个包装格式,里面的字体不是 ttf 就是 otf 的,所以真正的存储格式只有两种,ttf 和 otf。
这两种格式很明显都是二进制格式,没法直接打开看。但是,幸运的是,字体有一个格式叫做 ttx,是一个 XML 的可读格式。
我们的基本思路是:
- 裁剪字体:根据一个基础字体裁剪掉我们不需要的字符,比如斗鱼这种情况,我们只需要数字即可
- 将字体转换成
ttx格式打开 - 找到字符和图形的映射
- 修改这个映射
- 再导出字体为
ttf
这里我们使用 fonttools 这个强大的 Python 库来进行后续的操作。
我们以开源字体 Hack 为例。
我们先来裁剪字体。安装好 fonttools 以后会默认安装几个工具,其中之一是 pyftsubset,这个工具就可以用来裁剪字体。
$ pyftsubset hack.ttf --text="0123456789"
WARNING: TTFA NOT subset; don't know how to subset; dropped
上面的 warning 不用介意,运行完毕之后我们得到了 hack.subset.ttf,这个便是裁剪后的字体,只支持渲染 0 ~ 9。
接下来转换字体为可读的 ttx 格式。同样,fonttools 自带了一个工具叫做 ttx,直接使用即可。
$ ttx hack.subset.ttf
Dumping "hack.subset.ttf" to "hack.subset.ttx"...
Dumping 'GlyphOrder' table...
Dumping 'head' table...
Dumping 'hhea' table...
Dumping 'maxp' table...
Dumping 'OS/2' table...
Dumping 'hmtx' table...
Dumping 'cmap' table...
Dumping 'fpgm' table...
Dumping 'prep' table...
Dumping 'cvt ' table...
Dumping 'loca' table...
Dumping 'glyf' table...
Dumping 'name' table...
Dumping 'post' table...
Dumping 'gasp' table...
Dumping 'GSUB' table...
我们会发现目录下多了一个 hack.subset.ttx 文件,打开观察一下。
很容易就可以发现,cmap 标签中定义了字符和图形的映射。
<cmap>
<tableVersion version="0"/>
<cmap_format_4 platformID="0" platEncID="3" language="0">
<map code="0x30" name="zero"/><!-- DIGIT ZERO -->
<map code="0x31" name="one"/><!-- DIGIT ONE -->
<map code="0x32" name="two"/><!-- DIGIT TWO -->
<map code="0x33" name="three"/><!-- DIGIT THREE -->
<map code="0x34" name="four"/><!-- DIGIT FOUR -->
<map code="0x35" name="five"/><!-- DIGIT FIVE -->
<map code="0x36" name="six"/><!-- DIGIT SIX -->
<map code="0x37" name="seven"/><!-- DIGIT SEVEN -->
<map code="0x38" name="eight"/><!-- DIGIT EIGHT -->
<map code="0x39" name="nine"/><!-- DIGIT NINE -->
</cmap_format_4>
...
</cmap>
0x30 也就是字符 0 对应 name="zero" 的 TTGlyph,TTGlyph 中定义了渲染要用的数据,也就是一些坐标。
<TTGlyph name="zero" xMin="123" yMin="-29" xMax="1110" yMax="1520">
<contour>
<pt x="617" y="-29" on="1"/>
<pt x="369" y="-29" on="0"/>
<pt x="246" y="165" on="1"/>
<pt x="123" y="358" on="0"/>
<pt x="123" y="745" on="1"/>
<pt x="123" y="1134" on="0"/>
<pt x="246" y="1327" on="1"/>
<pt x="369" y="1520" on="0"/>
<pt x="616" y="1520" on="1"/>
<pt x="864" y="1520" on="0"/>
<pt x="987" y="1327" on="1"/>
<pt x="1110" y="1134" on="0"/>
<pt x="1110" y="745" on="1"/>
<pt x="1110" y="-29" on="0"/>
</contour>
...
</TTGlyph>
那么怎么制作混淆字体的方法就不言而喻了,我们修改一下这个 XML,把 TTGlyph(name="zero") 标签的 zero 换成 eight 然后把 TTGlyph(name="eight") 标签的 eight 换成 zero,保存文件为 fake.ttx。
导出 ttx 到 ttf 依然是使用 ttx 工具。
$ ttx -o fake.ttf fake.ttx
Compiling "fake.ttx" to "fake.ttf"...
Parsing 'GlyphOrder' table...
Parsing 'head' table...
Parsing 'hhea' table...
Parsing 'maxp' table...
Parsing 'OS/2' table...
Parsing 'hmtx' table...
Parsing 'cmap' table...
Parsing 'fpgm' table...
Parsing 'prep' table...
Parsing 'cvt ' table...
Parsing 'loca' table...
Parsing 'glyf' table...
Parsing 'name' table...
Parsing 'post' table...
Parsing 'gasp' table...
Parsing 'GSUB' table...
使用上文提到的 HTML 使用 fake.ttf 渲染 0 ~ 9,可以看到,我们成功地制作了一个混淆字体。
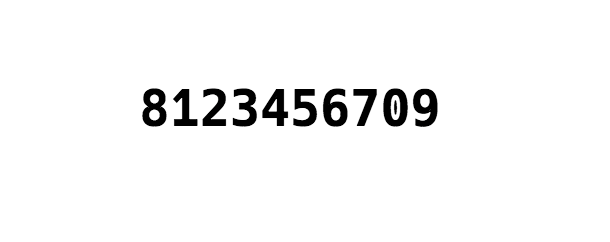
genfont.py 是我使用 Python 编写的脚本,可以自动生成任意数量的混淆字体。
# 使用 hack.subset.ttf 为基础生成 20 个混淆字体
$ ./genfont.py hack.subset.ttf 20
....
$ ls result/generated # 结果存储在这个目录中
0018fb8365.7149586203.ttf 267ccb0e95.8402759136.ttf
08a9457ab9.3958406712.ttf 281ef45f09.2154786390.ttf
1bbdd405ca.9147328650.ttf 788e0c7651.8790526413.ttf
1f985cd725.6417320895.ttf 5433d36fde.1326570894.ttf
2d56def315.8962135047.ttf 6844549191.3597082416.ttf
6bd27a4bac.0658392147.ttf a422833064.8416930752.ttf
6e337094a4.0754261839.ttf c7f0591c38.5761804329.ttf
9a0e22d6ad.9173452860.ttf d3269bd2ce.0384976152.ttf
9a407f17c1.8379426105.ttf f97691cc25.1587964230.ttf
44a428c37d.3602974581.ttf ffe2c54286.6894312057.ttf
文件名的形式为 fontID.mapping.ttf。比如 0018fb8365.7149586203.ttf 这个字体会将 0 渲染为 7。